glasses.nn package¶
Subpackages¶
Module contents¶
- class glasses.nn.Conv2dPad(*args, mode: str = 'auto', padding: int = 0, **kwargs)[source]¶
Bases:
torch.nn.modules.conv.Conv2d2D Convolutions with different padding modes.
‘auto’ will use the kernel_size to calculate the padding ‘same’ same padding as TensorFLow. It will dynamically pad the image based on its size
- Parameters
mode (str, optional) – [description]. Defaults to ‘auto’.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- bias: Optional[torch.Tensor]¶
- dilation: Tuple[int, ...]¶
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- groups: int¶
- kernel_size: Tuple[int, ...]¶
- out_channels: int¶
- output_padding: Tuple[int, ...]¶
- padding: Union[str, Tuple[int, ...]]¶
- padding_mode: str¶
- stride: Tuple[int, ...]¶
- transposed: bool¶
- weight: torch.Tensor¶
- class glasses.nn.ConvBnAct(in_features: int, out_features: int, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, conv: torch.nn.modules.module.Module = <class 'glasses.nn.blocks.Conv2dPad'>, normalization: torch.nn.modules.module.Module = <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, bias: bool = False, **kwargs)[source]¶
Bases:
torch.nn.modules.container.SequentialUtility module that stacks one convolution layer, a normalization layer and an activation function.
Example
>>> ConvBnAct(32, 64, kernel_size=3) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (act): ReLU() )
>>> ConvBnAct(32, 64, kernel_size=3, normalization = None ) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (act): ReLU() )
>>> ConvBnAct(32, 64, kernel_size=3, activation = None ) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) )
We also provide additional modules built on top of this one: ConvBn, ConvAct, Conv3x3BnAct :param out_features: Number of input features :type out_features: int :param out_features: Number of output features :type out_features: int :param conv: Convolution layer. Defaults to Conv2dPad. :type conv: nn.Module, optional :param normalization: Normalization layer. Defaults to nn.BatchNorm2d. :type normalization: nn.Module, optional :param activation: Activation function. Defaults to nn.ReLU. :type activation: nn.Module, optional
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.nn.DropBlock(block_size: int = 7, p: float = 0.5)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Drop Block proposed in DropBlock: A regularization method for convolutional networks
Similar to dropout but it maskes clusters of close pixels. The following image shows the approach (from the paper)

The following picture shows the effect of DropBlock on an input image

Note
[From the paper] We found that DropBlock with a fixed keep_prob during training does not work well. Applying small value of keep_prob hurts learning at the beginning. Instead, gradually decreasing keep_prob over time from 1 to the target value is more robust and adds improvement for the most values of keep_prob. In our experiments, we use a linear scheme of decreasing the value of keep_prob, which tends to work well across many hyperparameter settings. This linear scheme is similar to ScheduledDropPath.
keep_prob is p in our implementation.
- Parameters
block_size (int, optional) – Dimension of the pixel cluster. Defaults to 7.
p (float, optional) – probability, the bigger the mode clusters. Defaults to 0.5.
- calculate_gamma(x: torch.Tensor) float[source]¶
Compute gamma, eq (1) in the paper
- Parameters
x (Tensor) – Input tensor
- Returns
gamma
- Return type
Tensor
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.SpatialPyramidPool(num_pools: List[int] = [1, 4, 16], pool: torch.nn.modules.module.Module = <class 'torch.nn.modules.pooling.AdaptiveMaxPool2d'>)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
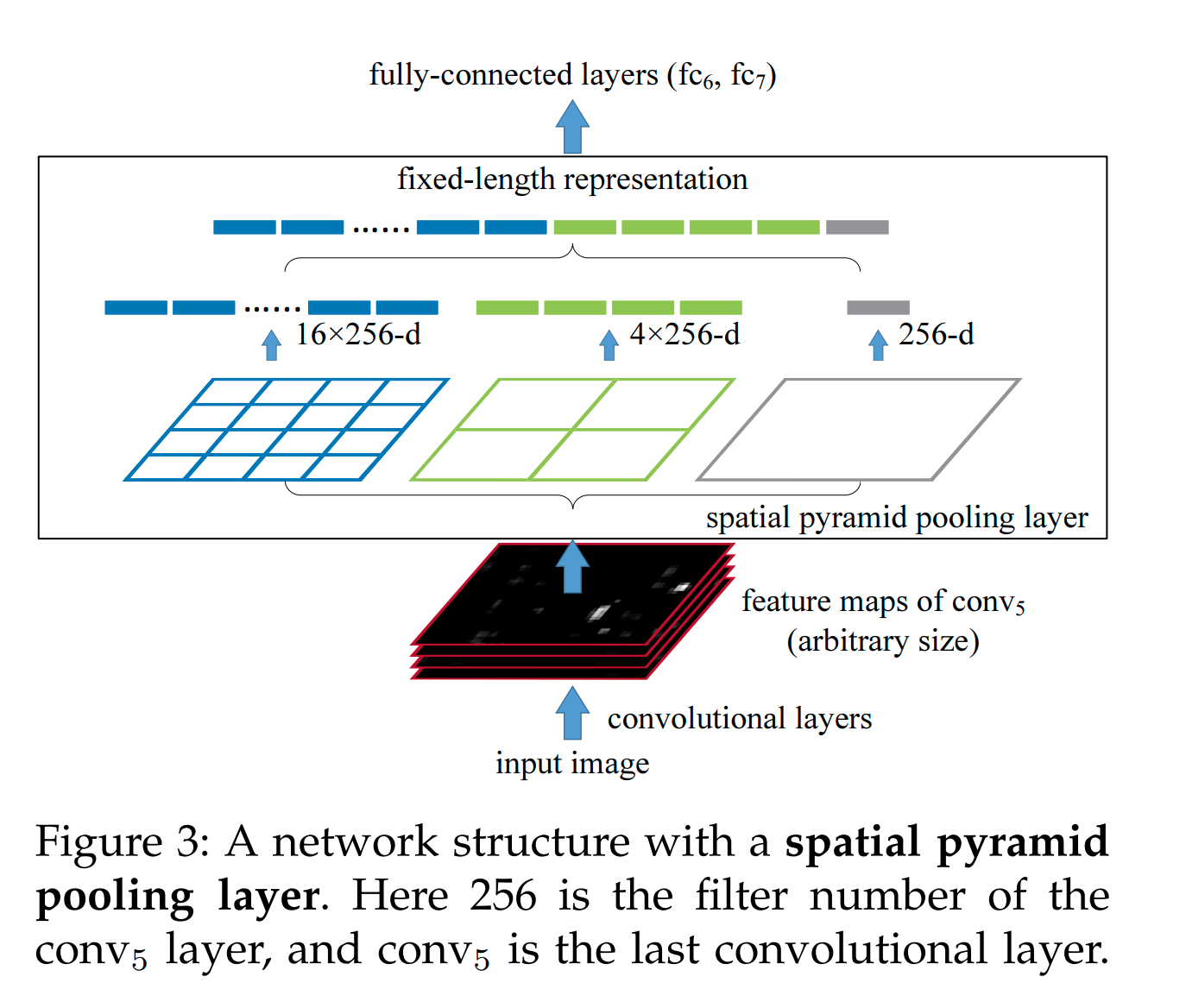
It generate fixed length representation regardless of image dimensions.
Examples
>>> x = torch.randn((4, 256, 14, 14)) >>> SpatialPyramidPool()(x).shape >>> # torch.Size([4, 256, 21])
- Parameters
num_pools (List[int], optional) – The number of pooling output size. Defaults to [1, 4, 16].
pool (nn.Module, optional) – The pooling layer. Defaults to nn.AdaptiveMaxPool2d.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.StochasticDepth(p: float = 0.5)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Stochastic Depth proposed in Deep Networks with Stochastic Depth.
The main idea is to skip one layer completely.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶