glasses.models.classification.vit package¶
Module contents¶
- class glasses.models.classification.vit.FeedForwardBlock(emb_size: int, expansion: int = 4, drop_p: float = 0.0, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>)[source]¶
Bases:
torch.nn.modules.container.SequentialInitializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.models.classification.vit.MultiHeadAttention(emb_size: int = 768, num_heads: int = 12, att_drop_p: float = 0.0, projection_drop_p: float = 0.2, qkv_bias: bool = False)[source]¶
Bases:
torch.nn.modules.module.ModuleClassic multi head attention proposed in Attention Is All You Need
- Parameters
emb_size (int, optional) – Embedding dimensions Defaults to 768.
num_heads (int, optional) – Number of heads. Defaults to 12.
att_drop_p (float, optional) – Attention dropout probability. Defaults to 0..
projection_drop_p (float, optional) – Projection dropout probability. Defaults to 0..
qkv_bias (bool, optional) – If yes, apply bias to the qkv projection matrix. Defaults to False.
- forward(x: torch.Tensor, mask: Optional[torch.Tensor] = None) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.models.classification.vit.PatchEmbedding(in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224, tokens: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.ViTTokens'>)[source]¶
Bases:
torch.nn.modules.module.ModulePatch Embedding layer used in ViT. In order to work with transformers, this layer decompose the input in multiple patches, add class token parameter and a position encoding (both learnable) and flat them.
The following image from the authors shows the architecture.
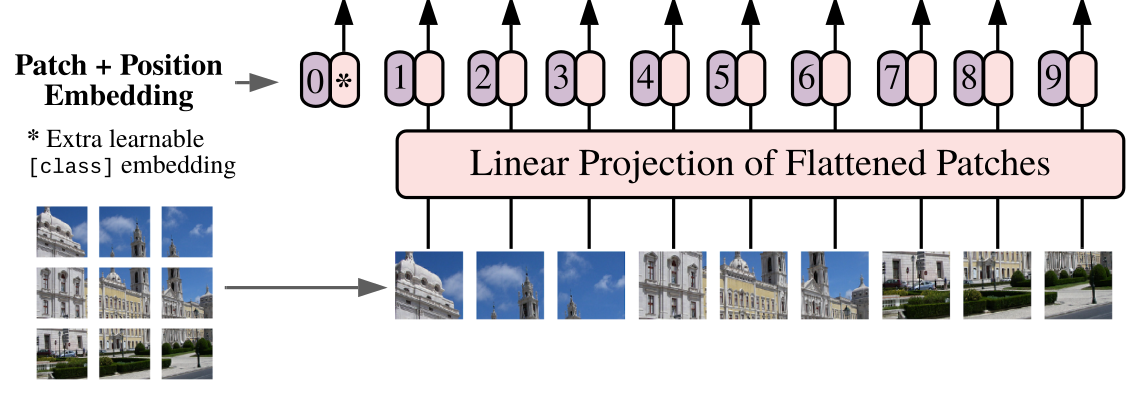
Example
# Change the tokens class MyTokens(ViTTokens): def __init__(self, emb_size: int): super().__init__(emb_size) self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size)) PatchEmbedding(tokens=MyTokens)
- Parameters
in_channels (int, optional) – Number of input’s channels. Defaults to 3.
patch_size (int, optional) – Size of the each patch. Defaults to 16.
emb_size (int, optional) – Embedding dimensions Defaults to 768.
img_size (int, optional) – Size of the input image, this is needed to calculate the final number of patches. Defaults to 224.
tokens (nn.Module, optional) – A module that contains the tokens as his parameters. Defaults to ViTTokens.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.models.classification.vit.ResidualAdd(fn)[source]¶
Bases:
torch.nn.modules.module.ModuleInitializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x, **kwargs)[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.models.classification.vit.TransformerEncoder(depth: int = 12, emb_size: int = 786, block: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.TransformerEncoderBlock'>, **kwargs)[source]¶
Bases:
glasses.models.base.EncoderTransformer Encoder proposed in Attention Is All You Need
Warning
Even if TransformerEncoder uses the Encoder APIs you won’t be able to use it with segmentation models since they will expect 3-D tensors as inputs.
- Parameters
depth (int, optional) – Number of transformer’s blocks. Defaults to 12.
block (nn.Module, optional) – Block used inside the transformer encoder. Defaults to TransformerEncoderBlock.
emb_size (int, optional) – Embedding dimensions Defaults to 768.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.models.classification.vit.TransformerEncoderBlock(emb_size: int = 768, forward_expansion: int = 4, forward_drop_p: float = 0.2, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.GELU'>, **kwargs)[source]¶
Bases:
torch.nn.modules.container.SequentialTransformer Encoder block proposed in Attention Is All You Need
The following image from the authors shows the architecture.
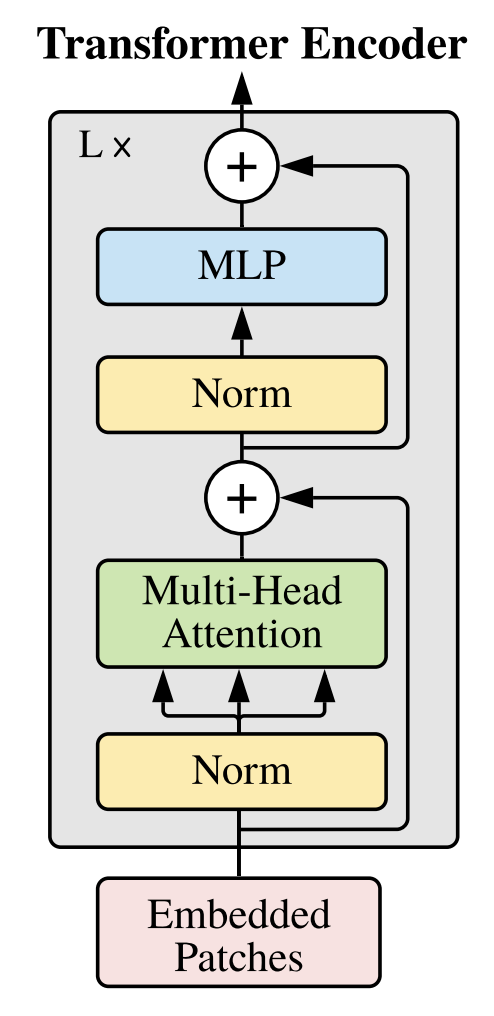
- Parameters
emb_size (int, optional) – Embedding dimensions Defaults to 768.
forward_expansion (int, optional) – [description]. Defaults to 4.
forward_drop_p (float, optional) – [description]. Defaults to 0..
- class glasses.models.classification.vit.ViT(embedding: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.PatchEmbedding'>, encoder: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.TransformerEncoder'>, head: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.ViTClassificationHead'>, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224, tokens: torch.nn.modules.module.Module = <class 'glasses.models.classification.vit.ViTTokens'>, depth: int = 12, n_classes: int = 1000, **kwargs)[source]¶
Bases:
torch.nn.modules.container.Sequential,glasses.models.base.VisionModuleImplementation of Vision Transformer (ViT) proposed in An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
The following image from the authors shows the architecture.

ViT.vit_small_patch16_224() ViT.vit_base_patch16_224() ViT.vit_base_patch16_384() ViT.vit_base_patch32_384() ViT.vit_huge_patch16_224() ViT.vit_huge_patch32_384() ViT.vit_large_patch16_224() ViT.vit_large_patch16_384() ViT.vit_large_patch32_384()
Examples
# change activation ViT.vit_base_patch16_224(activation = nn.SELU) # change number of classes (default is 1000 ) ViT.vit_base_patch16_224(n_classes=100) # pass a different block, default is TransformerEncoderBlock ViT.vit_base_patch16_224(block=MyCoolTransformerBlock) # get features model = ViT.vit_base_patch16_224 # first call .features, this will activate the forward hooks and tells the model you'll like to get the features model.encoder.features model(torch.randn((1,3,224,224))) # get the features from the encoder features = model.encoder.features print([x.shape for x in features]) #[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...] # change the tokens, you have to subclass ViTTokens class MyTokens(ViTTokens): def __init__(self, emb_size: int): super().__init__(emb_size) self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size)) ViT(tokens=MyTokens)
- Parameters
in_channels (int, optional) – [description]. Defaults to 3.
patch_size (int, optional) – [description]. Defaults to 16.
emb_size (int, optional) – Embedding dimensions Defaults to 768.
img_size (int, optional) – [description]. Defaults to 224.
tokens (nn.Module, optional) – A module that contains the tokens as his parameters. Defaults to ViTTokens.
depth (int, optional) – [description]. Defaults to 12.
n_classes (int, optional) – [description]. Defaults to 1000.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.models.classification.vit.ViTClassificationHead(emb_size: int = 768, n_classes: int = 1000, policy: str = 'token')[source]¶
Bases:
torch.nn.modules.container.SequentialViT Classification Head
- Parameters
emb_size (int, optional) – Embedding dimensions Defaults to 768.
n_classes (int, optional) – [description]. Defaults to 1000.
policy (str, optional) – Pooling policy, can be token or mean. Defaults to ‘token’.
- POLICIES = ['token', 'mean']¶
- class glasses.models.classification.vit.ViTTokens(emb_size: int)[source]¶
Bases:
torch.nn.modules.module.ModuleInitializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) List[torch.Tensor][source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶