glasses.nn.blocks package¶
Submodules¶
glasses.nn.blocks.residuals module¶
- glasses.nn.blocks.residuals.Cat2d = functools.partial(<class 'glasses.nn.blocks.residuals.InputForward'>, aggr_func=<function <lambda>>)¶
Pass the input to multiple modules and concatenates the output, for 1D input you can use Cat, while for 2D inputs, such as images, you can use Cat2d.
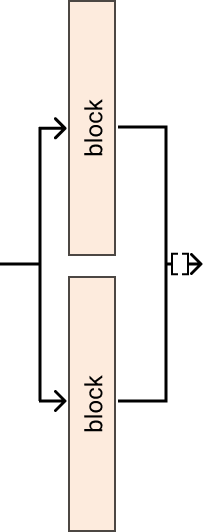
Examples
>>> blocks = nn.ModuleList([nn.Conv2d(32, 64, kernel_size=3), nn.Conv2d(32, 64, kernel_size=3)]) >>> x = torch.rand(1, 32, 48, 48) >>> Cat2d(blocks)(x).shape # torch.Size([1, 128, 46, 46])
- class glasses.nn.blocks.residuals.InputForward(blocks: torch.nn.modules.module.Module, aggr_func: Callable[[torch.Tensor], torch.Tensor])[source]¶
Bases:
torch.nn.modules.module.ModuleThis module passes the input to multiple modules and applies a aggregation function on the result.
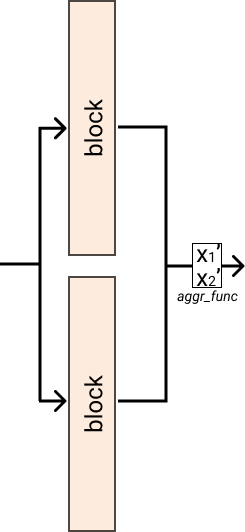
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.blocks.residuals.Residual(block: torch.nn.modules.module.Module, res_func: Optional[Callable[[torch.Tensor], torch.Tensor]] = None, shortcut: Optional[torch.nn.modules.module.Module] = None, *args, **kwargs)[source]¶
Bases:
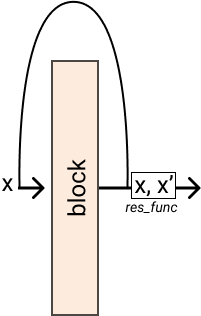
torch.nn.modules.module.ModuleIt applies residual connection to a nn.Module where the output becomes
\(y = F(x) + x\)
Examples
>>> block = nn.Identity() // does nothing >>> res = Residual(block, res_func=lambda x, res: x + res) >>> res(x) // tensor([2])
You can also pass a shortcut function
>>> res = Residual(block, res_func=lambda x, res: x + res, shortcut=lambda x: x * 2) >>> res(x) // tensor([3])
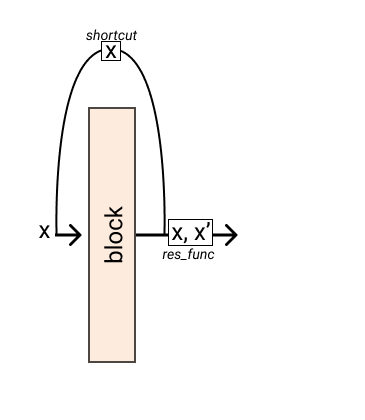
- Parameters
block (nn.Module) – A Pytorch module
res_func (Callable[[Tensor], Tensor], optional) – The residual function. Defaults to None.
shortcut (nn.Module, optional) – A function applied before the input is passed to block. Defaults to None.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.blocks.residuals.ResidualAdd(*args, **kwags)[source]¶
Bases:
glasses.nn.blocks.residuals.Residual- Parameters
block (nn.Module) – A Pytorch module
res_func (Callable[[Tensor], Tensor], optional) – The residual function. Defaults to None.
shortcut (nn.Module, optional) – A function applied before the input is passed to block. Defaults to None.
- training: bool¶
Module contents¶
- class glasses.nn.blocks.BnActConv(in_features: int, out_features: int, conv: torch.nn.modules.module.Module = <class 'glasses.nn.blocks.Conv2dPad'>, normalization: torch.nn.modules.module.Module = <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True), *args, **kwargs)[source]¶
Bases:
torch.nn.modules.container.SequentialA Sequential layer composed by a normalization, an activation and a convolution layer. This is usually known as a ‘Preactivation Block’
- Parameters
in_features (int) – Number of input features
out_features (int) – Number of output features
conv (nn.Module, optional) – [description]. Defaults to Conv2dPad.
normalization (nn.Module, optional) – [description]. Defaults to nn.BatchNorm2d.
activation (nn.Module, optional) – [description]. Defaults to nn.ReLU.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.nn.blocks.Conv2dPad(*args, mode: str = 'auto', padding: int = 0, **kwargs)[source]¶
Bases:
torch.nn.modules.conv.Conv2d2D Convolutions with different padding modes.
‘auto’ will use the kernel_size to calculate the padding ‘same’ same padding as TensorFLow. It will dynamically pad the image based on its size
- Parameters
mode (str, optional) – [description]. Defaults to ‘auto’.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- bias: Optional[torch.Tensor]¶
- dilation: Tuple[int, ...]¶
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- groups: int¶
- kernel_size: Tuple[int, ...]¶
- out_channels: int¶
- output_padding: Tuple[int, ...]¶
- padding: Union[str, Tuple[int, ...]]¶
- padding_mode: str¶
- stride: Tuple[int, ...]¶
- training: bool¶
- transposed: bool¶
- weight: torch.Tensor¶
- class glasses.nn.blocks.ConvBnAct(in_features: int, out_features: int, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, conv: torch.nn.modules.module.Module = <class 'glasses.nn.blocks.Conv2dPad'>, normalization: torch.nn.modules.module.Module = <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, bias: bool = False, **kwargs)[source]¶
Bases:
torch.nn.modules.container.SequentialUtility module that stacks one convolution layer, a normalization layer and an activation function.
Example
>>> ConvBnAct(32, 64, kernel_size=3) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (act): ReLU() )
>>> ConvBnAct(32, 64, kernel_size=3, normalization = None ) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (act): ReLU() )
>>> ConvBnAct(32, 64, kernel_size=3, activation = None ) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) )
We also provide additional modules built on top of this one: ConvBn, ConvAct, Conv3x3BnAct :param out_features: Number of input features :type out_features: int :param out_features: Number of output features :type out_features: int :param conv: Convolution layer. Defaults to Conv2dPad. :type conv: nn.Module, optional :param normalization: Normalization layer. Defaults to nn.BatchNorm2d. :type normalization: nn.Module, optional :param activation: Activation function. Defaults to nn.ReLU. :type activation: nn.Module, optional
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.nn.blocks.ConvBnDropAct(in_features: int, out_features: int, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, conv: torch.nn.modules.module.Module = <class 'glasses.nn.blocks.Conv2dPad'>, normalization: torch.nn.modules.module.Module = <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, regularization: torch.nn.modules.module.Module = <class 'glasses.nn.regularization.DropBlock'>, p: float = 0.2, bias: bool = False, **kwargs)[source]¶
Bases:
torch.nn.modules.container.SequentialUtility module that stacks one convolution layer, a normalization layer, a regularization layer and an activation function.
Example
>>> ConvBnDropAct(32, 64, kernel_size=3) ConvBnAct( (conv): Conv2dPad(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (reg): DropBlock(p=0.2) (act): ReLU() )
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- class glasses.nn.blocks.Lambda(lambd: Callable[[torch.Tensor], torch.Tensor])[source]¶
Bases:
torch.nn.modules.module.ModuleAn utility Module, it allows custom function to be passed
- Parameters
lambd (Callable[Tensor]) – A function that does something on a tensor
Examples
>>> add_two = Lambda(lambd x: x + 2) >>> add_two(Tensor([0])) // 2
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶