glasses.nn.att package¶
Submodules¶
glasses.nn.att.CBAM module¶
- class glasses.nn.att.CBAM.CBAM(features: int, reduction: int = 16, reduced_features: Optional[int] = None, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, kernel_size: int = 7)[source]¶
Bases:
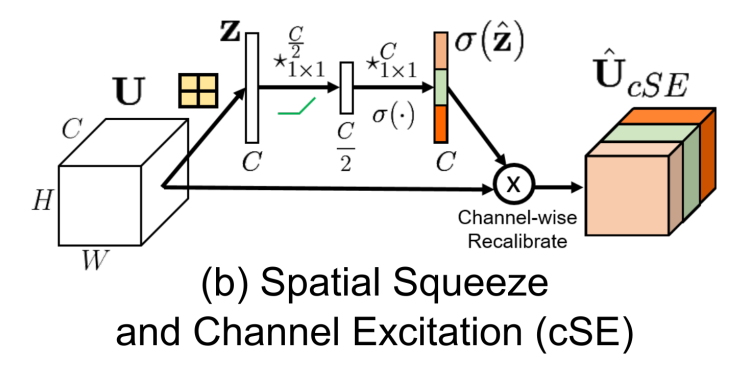
torch.nn.modules.module.ModuleImplementation of Convolutional Block Attention Module proposed in CBAM: Convolutional Block Attention Module
Examples
>>> # create cbamresnet50 >>> from glasses.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import CBAM, WithAtt >>> cbam_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=CBAM)) >>> cbam_resnet50.summary()
- Parameters
features (int, optional) – Number of features features. Defaults to None.
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
kernel_size (int, optional) – kernel_size of the Conv2d to produce the 2D spatial attention map. Defaults to 7.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.CBAM.CBAMChannelAtt(features: int, reduction: int = 16, reduced_features: Optional[int] = None, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>)[source]¶
Bases:
torch.nn.modules.module.ModuleInitializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.CBAM.CBAMSpatialAtt(kernel_size: int = 7)[source]¶
Bases:
torch.nn.modules.module.ModuleInitializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
glasses.nn.att.ECA module¶
- class glasses.nn.att.ECA.ECA(features: int, kernel_size: int = 3, gamma: int = 2, beta: int = 1)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Efficient Channel Attention proposed in ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
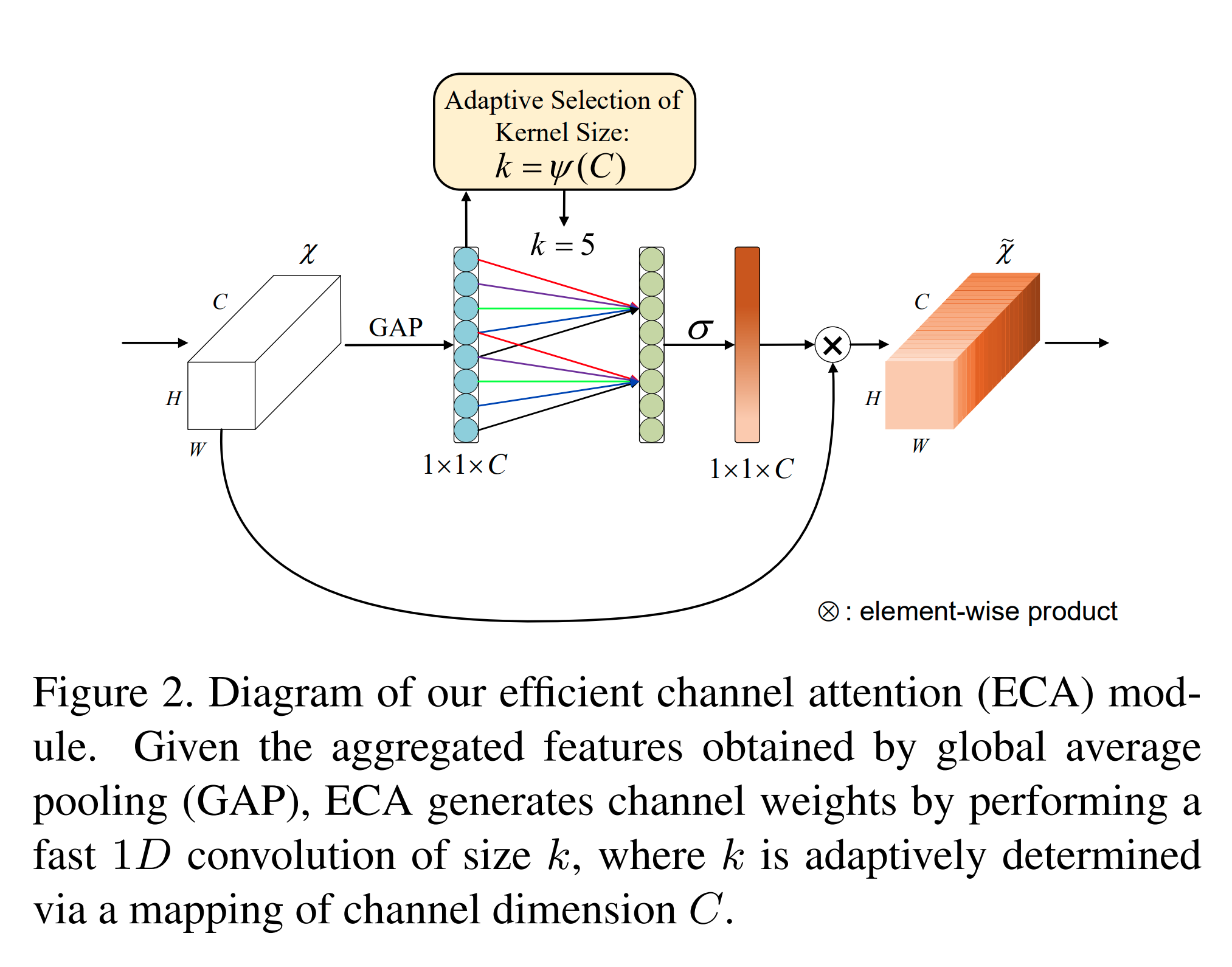
Examples
>>> # create ecaresnet50 >>> from glasses.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> eca_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=ECA)) >>> eca_resnet50.summary()
- Parameters
features (int, optional) – Number of features features. Defaults to None.
kernel_size (int, optional) – [description]. Defaults to 3.
gamma (int, optional) – [description]. Defaults to 2.
beta (int, optional) – [description]. Defaults to 1.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
glasses.nn.att.se module¶
- class glasses.nn.att.se.ChannelSE(features: int, *args, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True), **kwargs)[source]¶
Bases:
glasses.nn.att.se.SpatialSEModified implementation of Squeeze and Excitation Module proposed in Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
It squeezes channel-wise and excitates spatially.
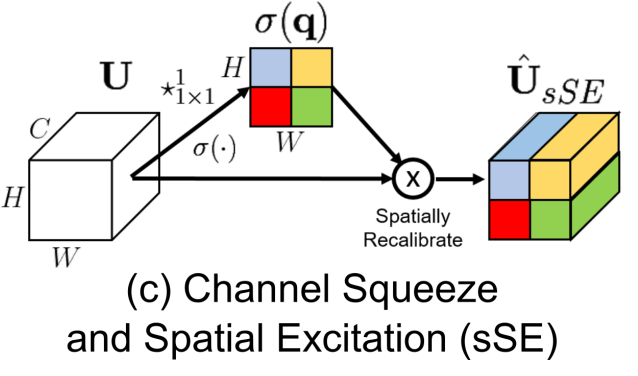
Examples
Add ChannelSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> ChannelSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> ChannelSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
Creating the cseresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=ChannelSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- training: bool¶
- class glasses.nn.att.se.LegacySpatialSE(features: int, *args, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True), **kwargs)[source]¶
Bases:
glasses.nn.att.se.SpatialSEImplementation of Squeeze and Excitation Module proposed in Squeeze-and-Excitation Networks
The idea is to apply a learned weight to rescale the channels.
It squeezes spatially and excitates channel-wise.
The authors reported a bigger performance increase where the number of features are higher.
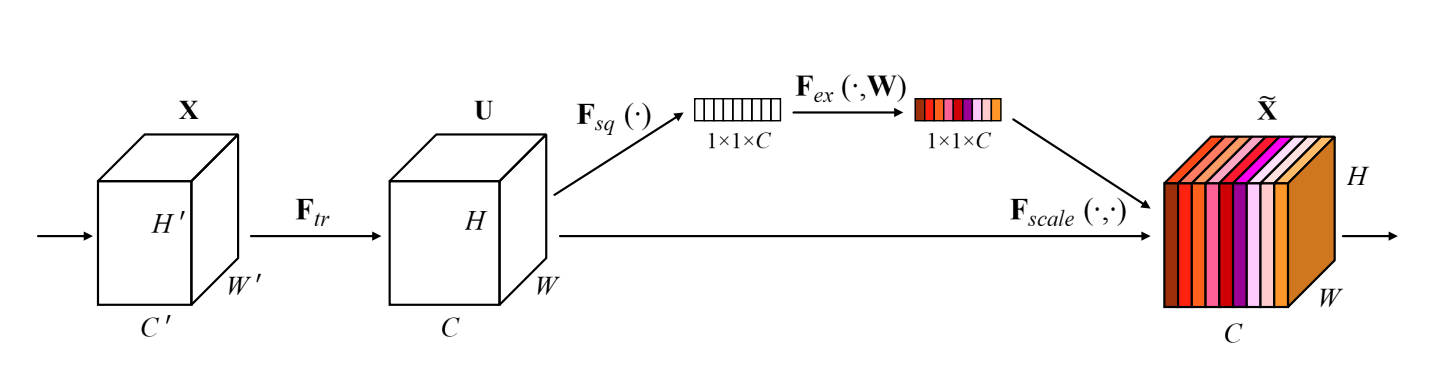
Further visualisation from Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
Examples
Add SpatialSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
The following example shows a more advance scenarion where we add Squeeze ad Excitation to a ResNetBasicBlock.
>>> class SENetBasicBlock(ResNetBasicBlock): >>> def __init__(self, in_features: int, out_features: int, reduction: int =16, *args, **kwargs): >>> super().__init__(in_features, out_features, *args, **kwargs) >>> # add se to the `.block` >>> self.block.add_module('se', SpatialSE(out_features))
Creating the original seresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=SpatialSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- training: bool¶
- class glasses.nn.att.se.SpatialChannelSE(*args, **kwargs)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Spatial and Channel Squeeze and Excitation Module proposed in Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
This module combines booth Spatial and Channel Squeeze and Excitation
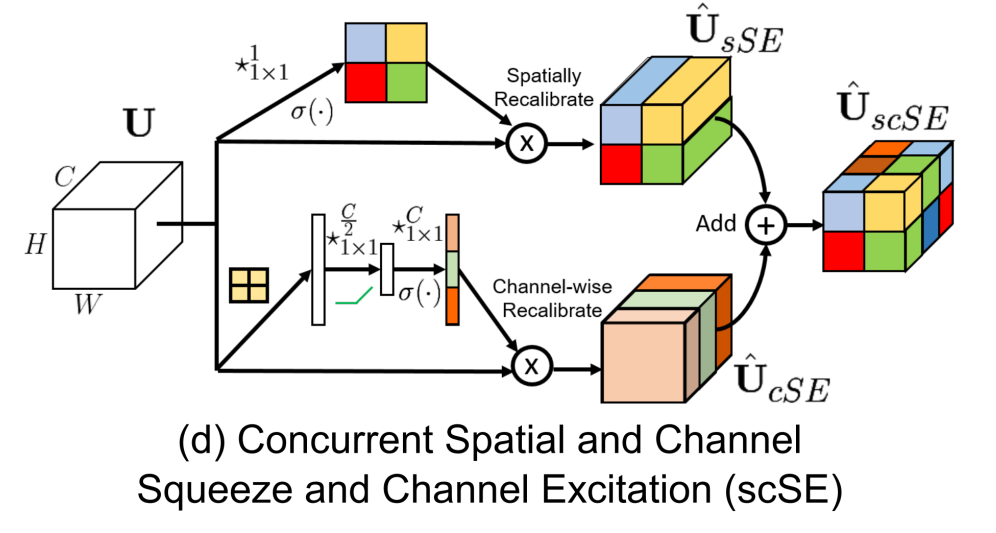
Examples
Add SpatialChannelSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialChannelSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialChannelSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
Creating scseresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=SpatialChannelSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.se.SpatialSE(features: int, reduction: int = 16, reduced_features: Optional[int] = None, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True))[source]¶
Bases:
torch.nn.modules.module.ModuleModernized Implementation of Squeeze and Excitation Module proposed in Squeeze-and-Excitation Networks with single kernel convolution instead of fully connected layers.
See LegacySpatialSE for usage.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
glasses.nn.att.utils module¶
- class glasses.nn.att.utils.WithAtt(block: torch.nn.modules.module.Module, att: torch.nn.modules.module.Module = <class 'glasses.nn.att.se.SpatialSE'>)[source]¶
Bases:
objectUtility class that adds an attention module after .block.
- Usage
>>> WithAtt(ResNetBottleneckBlock, att=SpatialSE) >>> WithAtt(ResNetBottleneckBlock, att=ECA) >>> from functools import partial >>> WithAtt(ResNetBottleneckBlock, att=partial(SpatialSE, reduction=8))
Module contents¶
- class glasses.nn.att.CBAM(features: int, reduction: int = 16, reduced_features: Optional[int] = None, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.ReLU'>, kernel_size: int = 7)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Convolutional Block Attention Module proposed in CBAM: Convolutional Block Attention Module
Examples
>>> # create cbamresnet50 >>> from glasses.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import CBAM, WithAtt >>> cbam_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=CBAM)) >>> cbam_resnet50.summary()
- Parameters
features (int, optional) – Number of features features. Defaults to None.
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
kernel_size (int, optional) – kernel_size of the Conv2d to produce the 2D spatial attention map. Defaults to 7.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.ChannelSE(features: int, *args, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True), **kwargs)[source]¶
Bases:
glasses.nn.att.se.SpatialSEModified implementation of Squeeze and Excitation Module proposed in Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
It squeezes channel-wise and excitates spatially.
Examples
Add ChannelSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> ChannelSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> ChannelSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
Creating the cseresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=ChannelSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- training: bool¶
- class glasses.nn.att.ECA(features: int, kernel_size: int = 3, gamma: int = 2, beta: int = 1)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Efficient Channel Attention proposed in ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Examples
>>> # create ecaresnet50 >>> from glasses.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> eca_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=ECA)) >>> eca_resnet50.summary()
- Parameters
features (int, optional) – Number of features features. Defaults to None.
kernel_size (int, optional) – [description]. Defaults to 3.
gamma (int, optional) – [description]. Defaults to 2.
beta (int, optional) – [description]. Defaults to 1.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.LegacySpatialSE(features: int, *args, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True), **kwargs)[source]¶
Bases:
glasses.nn.att.se.SpatialSEImplementation of Squeeze and Excitation Module proposed in Squeeze-and-Excitation Networks
The idea is to apply a learned weight to rescale the channels.
It squeezes spatially and excitates channel-wise.
The authors reported a bigger performance increase where the number of features are higher.
Further visualisation from Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
Examples
Add SpatialSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
The following example shows a more advance scenarion where we add Squeeze ad Excitation to a ResNetBasicBlock.
>>> class SENetBasicBlock(ResNetBasicBlock): >>> def __init__(self, in_features: int, out_features: int, reduction: int =16, *args, **kwargs): >>> super().__init__(in_features, out_features, *args, **kwargs) >>> # add se to the `.block` >>> self.block.add_module('se', SpatialSE(out_features))
Creating the original seresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=SpatialSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- training: bool¶
- class glasses.nn.att.SpatialChannelSE(*args, **kwargs)[source]¶
Bases:
torch.nn.modules.module.ModuleImplementation of Spatial and Channel Squeeze and Excitation Module proposed in Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
This module combines booth Spatial and Channel Squeeze and Excitation
Examples
Add SpatialChannelSE to your own model is very simple.
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialChannelSE(64, reduction=4) >>> nn.ReLU(), >>> )
You can also direcly specify the number of features inside the module
>>> nn.Sequential( >>> nn.Conv2d(32, 64, kernel_size=3), >>> SpatialChannelSE(64, reduced_features=10) >>> nn.ReLU(), >>> )
Creating scseresnet50
>>> from glasses.nn.models.classification.resnet import ResNet, ResNetBottleneckBlock >>> from glasses.nn.att import ECA, WithAtt >>> se_resnet50 = ResNet.resnet50(block=WithAtt(ResNetBottleneckBlock, att=SpatialChannelSE)) >>> se_resnet50.summary()
- Parameters
features (int) – Number of features
reduction (int, optional) – Reduction ratio used to downsample the input. Defaults to 16.
reduced_features (int, optional) – If passed, use it instead of calculating the reduced features using reduction. Defaults to None.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.SpatialSE(features: int, reduction: int = 16, reduced_features: Optional[int] = None, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.ReLU'>, inplace=True))[source]¶
Bases:
torch.nn.modules.module.ModuleModernized Implementation of Squeeze and Excitation Module proposed in Squeeze-and-Excitation Networks with single kernel convolution instead of fully connected layers.
See LegacySpatialSE for usage.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶
- class glasses.nn.att.WithAtt(block: torch.nn.modules.module.Module, att: torch.nn.modules.module.Module = <class 'glasses.nn.att.se.SpatialSE'>)[source]¶
Bases:
objectUtility class that adds an attention module after .block.
- Usage
>>> WithAtt(ResNetBottleneckBlock, att=SpatialSE) >>> WithAtt(ResNetBottleneckBlock, att=ECA) >>> from functools import partial >>> WithAtt(ResNetBottleneckBlock, att=partial(SpatialSE, reduction=8))