glasses.models.classification.efficientnet package¶
Module contents¶
- class glasses.models.classification.efficientnet.EfficientNet(encoder: torch.nn.modules.module.Module = <class 'glasses.models.classification.efficientnet.EfficientNetEncoder'>, head: torch.nn.modules.module.Module = <class 'glasses.models.classification.efficientnet.EfficientNetHead'>, *args, **kwargs)[source]¶
Bases:
glasses.models.classification.base.ClassificationModuleImplementation of EfficientNet proposed in EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks

The basic architecture is similar to MobileNetV2 as was computed by using Progressive Neural Architecture Search .
The following table shows the basic architecture (EfficientNet-efficientnet_b0):

Then, the architecture is scaled up from -efficientnet_b0 to -efficientnet_b7 using compound scaling.

EfficientNet.efficientnet_b0() EfficientNet.efficientnet_b1() EfficientNet.efficientnet_b2() EfficientNet.efficientnet_b3() EfficientNet.efficientnet_b4() EfficientNet.efficientnet_b5() EfficientNet.efficientnet_b6() EfficientNet.efficientnet_b7() EfficientNet.efficientnet_b8() EfficientNet.efficientnet_l2()
Examples
EfficientNet.efficientnet_b0(activation = nn.SELU) # change number of classes (default is 1000 ) EfficientNet.efficientnet_b0(n_classes=100) # pass a different block EfficientNet.efficientnet_b0(block=...) # store each feature x = torch.rand((1, 3, 224, 224)) model = EfficientNet.efficientnet_b0() # first call .features, this will activate the forward hooks and tells the model you'll like to get the features model.encoder.features model(torch.randn((1,3,224,224))) # get the features from the encoder features = model.encoder.features print([x.shape for x in features]) # [torch.Size([1, 32, 112, 112]), torch.Size([1, 24, 56, 56]), torch.Size([1, 40, 28, 28]), torch.Size([1, 80, 14, 14])]
- Parameters
in_channels (int, optional) – Number of channels in the input Image (3 for RGB and 1 for Gray). Defaults to 3.
n_classes (int, optional) – Number of classes. Defaults to 1000.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- default_depths: List[int] = [1, 2, 2, 3, 3, 4, 1]¶
- default_widths: List[int] = [32, 16, 24, 40, 80, 112, 192, 320, 1280]¶
- classmethod efficientnet_b0(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b1(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b2(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b3(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b4(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b5(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b6(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b7(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_b8(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_l2(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod from_config(config, key, *args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- models_config = {'efficientnet_b0': (1.0, 1.0, 0.2), 'efficientnet_b1': (1.0, 1.1, 0.2), 'efficientnet_b2': (1.1, 1.2, 0.3), 'efficientnet_b3': (1.2, 1.4, 0.3), 'efficientnet_b4': (1.4, 1.8, 0.4), 'efficientnet_b5': (1.6, 2.2, 0.4), 'efficientnet_b6': (1.8, 2.6, 0.5), 'efficientnet_b7': (2.0, 3.1, 0.5), 'efficientnet_b8': (2.2, 3.6, 0.5), 'efficientnet_l2': (4.3, 5.3, 0.5)}¶
- training: bool¶
- glasses.models.classification.efficientnet.EfficientNetBasicBlock¶
alias of
glasses.models.classification.efficientnet.InvertedResidualBlock
- class glasses.models.classification.efficientnet.EfficientNetEncoder(in_channels: int = 3, widths: List[int] = [32, 16, 24, 40, 80, 112, 192, 320, 1280], depths: List[int] = [1, 2, 2, 3, 3, 4, 1], strides: List[int] = [2, 1, 2, 2, 2, 1, 2, 1], expansions: List[int] = [1, 6, 6, 6, 6, 6, 6], kernel_sizes: List[int] = [3, 3, 5, 3, 5, 5, 3], se: List[bool] = [True, True, True, True, True, True, True], drop_rate: float = 0.2, stem: torch.nn.modules.module.Module = <class 'glasses.nn.blocks.ConvBnAct'>, activation: torch.nn.modules.module.Module = functools.partial(<class 'torch.nn.modules.activation.SiLU'>, inplace=True), **kwargs)[source]¶
Bases:
glasses.models.base.EncoderEfficientNet encoder composed by multiple different layers with increasing features.
Be awere that widths and strides also includes the width and stride for the steam in the first position.
- Parameters
in_channels (int, optional) – [description]. Defaults to 3.
widths (List[int], optional) – [description]. Defaults to [32, 16, 24, 40, 80, 112, 192, 320, 1280].
depths (List[int], optional) – [description]. Defaults to [1, 2, 2, 3, 3, 4, 1].
strides (List[int], optional) – [description]. Defaults to [2, 1, 2, 2, 2, 1, 2, 1].
expansions (List[int], optional) – [description]. Defaults to [1, 6, 6, 6, 6, 6, 6].
kernel_sizes (List[int], optional) – [description]. Defaults to [3, 3, 5, 3, 5, 5, 3].
se (List[bool], optional) – [description]. Defaults to [True, True, True, True, True, True, True].
drop_rate (float, optional) – [description]. Defaults to 0.2.
activation (nn.Module, optional) – [description]. Defaults to nn.SiLU.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- property features_widths¶
- forward(x)[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- property stages¶
- training: bool¶
- class glasses.models.classification.efficientnet.EfficientNetHead(in_features: int, n_classes: int, drop_rate: float = 0.2)[source]¶
Bases:
torch.nn.modules.container.SequentialThis class represents the head of EfficientNet. It performs a global pooling, dropout and maps the output to the correct class by using a fully connected layer.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class glasses.models.classification.efficientnet.EfficientNetLite(encoder: torch.nn.modules.module.Module = <class 'glasses.models.classification.efficientnet.EfficientNetEncoder'>, head: torch.nn.modules.module.Module = <class 'glasses.models.classification.efficientnet.EfficientNetHead'>, *args, **kwargs)[source]¶
Bases:
glasses.models.classification.efficientnet.EfficientNetImplementations of EfficientNetLite proposed in Higher accuracy on vision models with EfficientNet-Lite
Main differences from the EfficientNet implementation are:
Removed squeeze-and-excitation networks since they are not well supported
Replaced all swish activations with RELU6, which significantly improved the quality of post-training quantization (explained later)
Fixed the stem and head while scaling models up in order to reduce the size and computations of scaled models
Examples
Create a default model
>>> EfficientNetLite.efficientnet_lite0() >>> EfficientNetLite.efficientnet_lite1() >>> EfficientNetLite.efficientnet_lite2() >>> EfficientNetLite.efficientnet_lite3() >>> EfficientNetLite.efficientnet_lite4()
- Parameters
in_channels (int, optional) – Number of channels in the input Image (3 for RGB and 1 for Gray). Defaults to 3.
n_classes (int, optional) – Number of classes. Defaults to 1000.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- classmethod efficientnet_lite0(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_lite1(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_lite2(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_lite3(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod efficientnet_lite4(*args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- classmethod from_config(config, key, *args, **kwargs) glasses.models.classification.efficientnet.EfficientNet[source]¶
- models_config = {'efficientnet_lite0': (1.0, 1.0, 0.2), 'efficientnet_lite1': (1.0, 1.1, 0.2), 'efficientnet_lite2': (1.1, 1.2, 0.3), 'efficientnet_lite3': (1.2, 1.4, 0.3), 'efficientnet_lite4': (1.4, 1.8, 0.3)}¶
- training: bool¶
- class glasses.models.classification.efficientnet.InvertedResidualBlock(in_features: int, out_features: int, stride: int = 1, expansion: int = 6, activation: torch.nn.modules.module.Module = <class 'torch.nn.modules.activation.SiLU'>, drop_rate: float = 0.2, se: bool = True, kernel_size: int = 3, **kwargs)[source]¶
Bases:
torch.nn.modules.module.ModuleInverted residual block proposed originally for MobileNetV2.
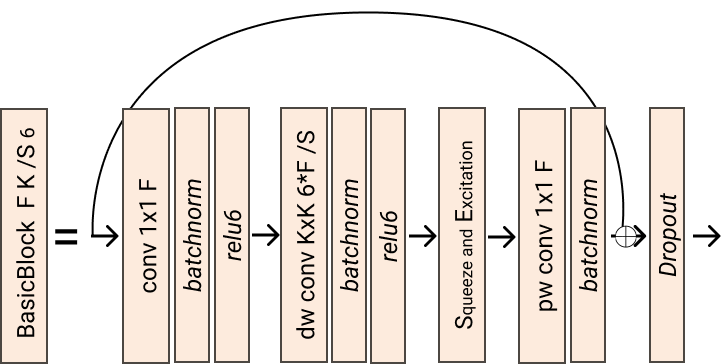
- Parameters
in_features (int) – Number of input features
out_features (int) – Number of output features
stride (int, optional) – Stide used in the depth convolution. Defaults to 1.
expansion (int, optional) – The expansion ratio applied. Defaults to 6.
activation (nn.Module, optional) – The activation funtion used. Defaults to nn.SiLU.
drop_rate (float, optional) – If > 0, add a nn.Dropout2d at the end of the block. Defaults to 0.2.
se (bool, optional) – If True, add a ChannelSE module after the depth convolution. Defaults to True.
kernel_size (int, optional) – [description]. Defaults to 3.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x: torch.Tensor) torch.Tensor[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- training: bool¶